1. Executor
一、原生JDBC执行流程
public void jdbcTest() throws SQLException {
// 1、获取连接
var connection = DriverManager.getConnection(URL, USERNAME, PASSWORD);
// 2、预编译
var sql = "SELECT * FROM users WHERE `name`=?";
var ps = connection.prepareStatement(sql);
ps.setString(1, "hayaking");
// 3、执行SQL
ps.execute();
// 4、获取结果集
var resultSet = ps.getResultSet();
while (resultSet.next()) {
System.out.println(resultSet.getString(1));
}
resultSet.close();
sql1.close();;
}
总结一下,流程如下:

其中,Connection、PreparedStatement、ResultSet这些都是jdk提供的。
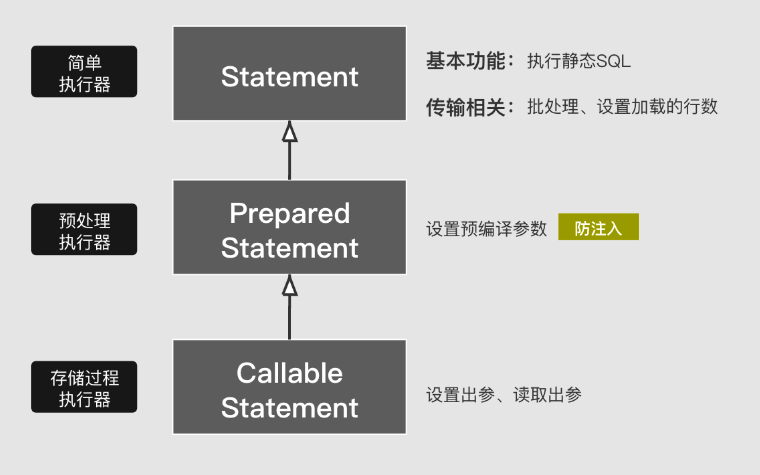
在jdk出的JDBC执行器规范接口中,Statement作为接口,PreparedStatement、CallableStatement分别是基于Statement的增强和扩展。
在使用层面:
- Statement:可以支持重用执行多个静态SQL,并可以设置addBatch、setFetchSize等操作。Statement的每次执行都是给数据库发送一个静态SQL。多次执行,即发送多个静态SQL。
- PreparedStatement:可以对SQL进行预编译,可以有效防止SQL注入。并且,每次执行都是给数据库发送一个SQL,加上若干组参数。
- CallableStatement:集成以上两个接口的基础上,扩展了返回结果的读写。
二、Mybatis执行流程
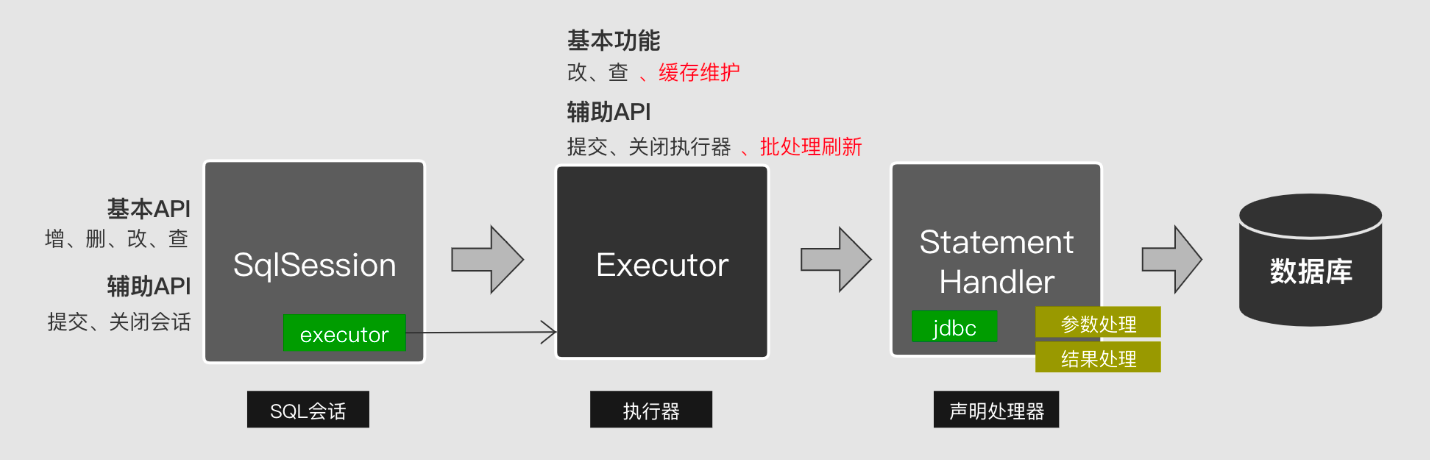
对照JDBC的标准流程,Mybatis将Connection对象维护交由SqlSession这个环节来处理,将SQL预编译与执行交给Executor这个环节来处理,将结果集提取交给StatemntHandler来处理。
三、Executor分类
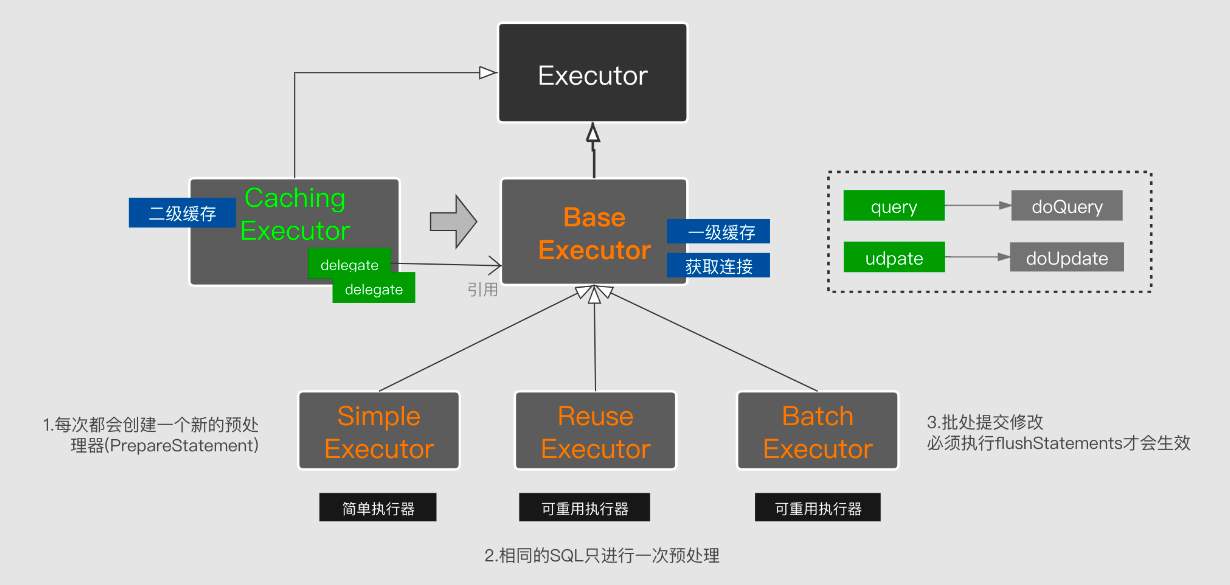
Executor是个接口,定义了修改(增删改)、查询、提交、回滚、缓存的基本规范。其子类根据分工不同对其做个差异化实现:
- BaseExecutor: 抽象类,其它executor都继承自该类。该类提供了连接维护、一级缓存的公有功能,供子类复用。并定义了doQuery、doUpdate的抽象方法让子类去实现
- CachingExecutor: BaseExecutor子类,持有别的executor,利用装饰器模式实现了二级缓存的功能,其它操作则会委托给持有的executor去执行。
- SimpleExecutor(默认): 每处理一次会话当中的SQl请求,都会通过对应的StatementHandler 构建一个新个Statement,这就会导致即使是相同SQL语句也无法重用Statement,所以就有了(ReuseExecutor)可重用执行器
- ReuseExecutor: 在会话期间内的Statement进行缓存,并使用SQL语句作为Key。所以当执行下一请求的时候,不在重复构建Statement,而是从缓存中取出并设置参数,然后执行
- BatchExecutor: 支持批量处理,每次需要手动flushStatement才能生效
四、缓存
myBatis中存在两个缓存,一级缓存和二级缓存。
查询缓存时,会先去查询二级缓存,再去查询一级缓存。
4.1一级缓存
也叫做会话级缓存,生命周期仅存在于当前会话,不可以直接关关闭。但可以通过flushCache和localCacheScope对其做相应控制。
localCacheScope默认是SESSION级别,即在一个MyBatis会话中执行的所有语句,都会共享这一个缓存。一种是STATEMENT级别,可以理解为缓存只对当前执行的这一个Statement有效。
4.1.1 命中场景
- SQL与参数相同
- 同一个会话
- 相同的MapperStatement ID
- RowBounds行范围相同
四个条件,缺一不可
4.1.2 触发清空缓存
以下操作会导致一级缓存被清空:
- 手动调用clearCache
- 执行提交回滚
- 执行update
- 配置flushCache=true
- 缓存作用域为Statement
4.1.3 实现原理
一级缓存的相关代码逻辑都在BaseExecutor中。
当会话接收到查询请求之后,会交给BaseExecutor的query方法
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
// 在这里会通过 Sql、参数、分页条件等参数创建一个缓存key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
// ...
List<E> list;
try {
queryStack++;
// 根据key查找缓存
// localCache是对hashmap的封装
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
// ...
}
何时会清空缓存
- update: 执行任意增删改
- select:查询又分为两种情况清空,一种是前置清空,即配置了flushCache=true。另一种后置清空,配置了缓存作用域为statement 查询结束合会清空缓存。
- commit:提交前清空
- rollback:回滚前清空
4.2 二级缓存
也叫应用级性缓存,而且可以跨线程使用,如果多个SqlSession之间需要共享缓存,则需要使用到二级缓存。
开启二级缓存后,会使用CachingExecutor装饰Executor,进入一级缓存的查询流程前,先在CachingExecutor进行二级缓存的查询。
4.2.1 实现原理
直接看CachingExecutor的源码
public class CachingExecutor implements Executor {
// 装饰器模式,持有的别的Executor, 除了二级缓存的操作,其他操作都会委托给这个Executor执行
private final Executor delegate;
// ...
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject);
// 获取缓存的key
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql);
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
@Override
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
// 获取二级缓存的Cache类
Cache cache = ms.getCache();
if (cache != null) {
// 然后是判断是否需要刷新缓存
flushCacheIfRequired(ms);
if (ms.isUseCache() && resultHandler == null) {
// ensureNoOutParams主要是用来处理存储过程的, 忽略
ensureNoOutParams(ms, boundSql);
// 尝试从tcm中获取缓存的列表
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key);
if (list == null) {
// 如果为空,就委托持有的executor查询
list = delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
// 并不是直接接结果放到二级缓存中
tcm.putObject(cache, key, list); // issue #578 and #116
}
return list;
}
}
return delegate.query(ms, parameterObject, rowBounds, resultHandler, key, boundSql);
}
Cache本身是一个接口,他有很多实现类,如下所示:
- SynchronizedCache:同步Cache,实现比较简单,直接使用synchronized修饰方法。
- LoggingCache:日志功能,装饰类,用于记录缓存的命中率,如果开启了DEBUG模式,则会输出命中率日志。
- SerializedCache:序列化功能,将值序列化后存到缓存中。该功能用于缓存返回一份实例的Copy,用于保存线程安全。
- LruCache:采用了Lru算法的Cache实现,移除最近最少使用的Key/Value。
- PerpetualCache: 作为为最基础的缓存类,底层实现比较简单,直接使用了HashMap。
在默认的设置中SELECT语句不会刷新缓存,insert/update/delete会刷新缓存。
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
tcm.putObject(cache, key, list),并不是直接接结果放到二级缓存中,具体可以看下源码
public void putObject(Cache cache, CacheKey key, Object value) {
getTransactionalCache(cache).putObject(key, value);
}
private TransactionalCache getTransactionalCache(Cache cache) {
return MapUtil.computeIfAbsent(transactionalCaches, cache, TransactionalCache::new);
}
向二级缓存的put的值会先放在TrancationalCache中,当事务commit时,才会将TrancationalCache中的值刷到二级缓存中