3. Producer
一、什么是Producer
负责生成并发送消息到kafka的一方称之为生产者(Producer)
二、生产者发送消息全流程
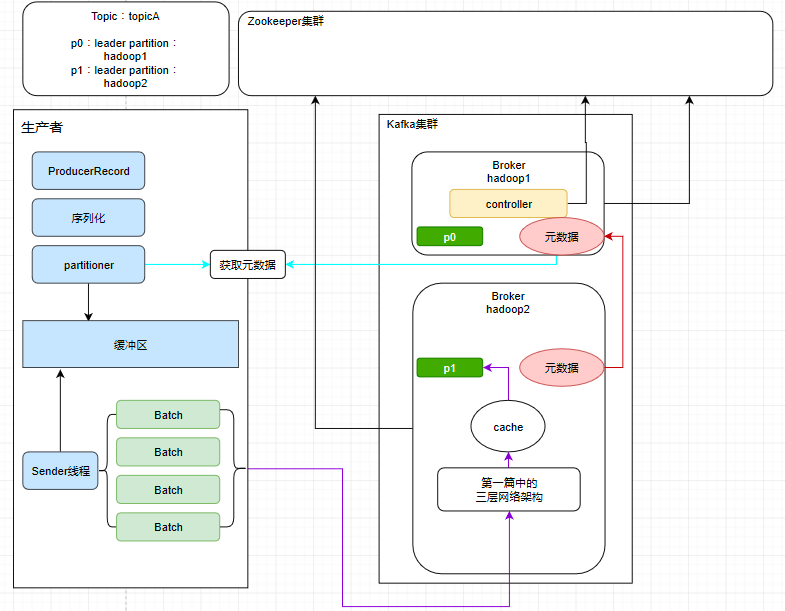
消息想从 Producer发送到 Broker,必须要先知道Topic在Broker的分布情况,才能判断消息该发往哪些节点,比如:
- Topic 对应的 Leader 分区有哪些
- Leader分区分布在哪些 Broker 节点
- Topic 分区动态变更等
所以Producer在向Broker发数据前会先获取以下topic的元数据,根据元数据再决定数据发给那个broker,具体流程如下:
- 将消息包装成ProducerRecord
- 序列化
- 获取topic元数据信息,分配消息写入到topic哪个分区上
- 缓冲区
- 发往同一个topic的消息会被放sender线程发送给对应的broker
- 服务器在收到这些消息时会返回一个响应 如果消息成功写入kafka,就返回一个RecordMetaData对象,它包含了主题和分区信息,以及记录在分区里的偏移量。 如果写入失败,则会返回一个错误。生产者在收到错误之后会尝试重新发送消息,几次之后如果还是失败,就返回错误信息。
三、生产者参数调优
| 参数名 | 作用 | 默认值 | 推荐值 |
| retries | 发送消息失败后,重试次数 | 3 | |
| retries.backoff.ms | 每次重试的时间间隔 | 100ms | |
| acks | 应答策略 -1 消息发送到leader分区,然后还需要被同步到ISR副本分区才算成功 0 消息被broker接收到就算成功 1 消息被leader分区接收到结算成功 | 1 | 1 |
| batch.size | 消息批次大小 | 16kb | |
| linger.ms | 超时等待时间 避免消息因为batch.size而迟迟没有发送出去 | 0ms | |
| buffer.memory | 缓冲区大小 如果缓冲区设置太小的话,容易满,一旦缓冲区满了,就会阻塞上游业务 | 32MB | |
| metadata.max.age.ms | 元数据过期时间 | 5分钟 |
四、拦截器
拦截即将发送的消息,可以在这里给消息做一些修改什么的
4.1 自定义拦截器
import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Map;
public class MyInterceptor implements ProducerInterceptor<String, String> {
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 在这里拦截并处理即将发给broker的消息
// record.topic()
// record.partition()
// record.timestamp()
// record.key()
// record.value()
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
五、序列化器
最常用的就是org.apache.kafka.common.serialization.StringSerializer,直接发送json字符串就行。
5.1 自定义序列化器
下面展示使用ByteBuffer存储对象值,最后转成byte数组的序列化方式。肯定是比json字符串省空间了,但是想支持复杂嵌套的结构可能不太行。此外producer这边如果自定义序列化器,那么consumer那边也要自定义反序列化器。
public class DemoSerializer implements Serializer<Company> {
public void configure(Map<String, ?> configs, boolean isKey) {}
public byte[] serialize(String topic, Company data) {
if (data == null) {
return null;
}
byte[] name, address;
try {
if (data.getName() != null) {
name = data.getName().getBytes("UTF-8");
} else {
name = new byte[0];
}
if (data.getAddress() != null) {
address = data.getAddress().getBytes("UTF-8");
} else {
address = new byte[0];
}
ByteBuffer buffer = ByteBuffer.allocate(4+4+name.length + address.length);
buffer.putInt(name.length);
buffer.put(name);
buffer.putInt(address.length);
buffer.put(address);
return buffer.array();
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return new byte[0];
}
public void close() {}
}
指定序列化器:
properties.put("value.serializer", "com.hidden.client.DemoSerializer");
六、分区器
!!网上的八股文好多错的
- DefaultPartitioner,默认分区器
- 如果有指定key,根据key的hashcode,与分区总数取余,根据计算结果选择分区。有key的情况下是这个策略
- 如果没有指定key,会随机选取一个分区,并缓存这个分区号保证之后一直发送给这个分区。StickyPartition 随机粘性分区
- RoundRobinPartitioner,轮询策略,消息会先发给第一个分区,然后再发给第二个....然后再从头。默认没有key的情况下是轮询策略
- UniformStickyPartitioner,纯粹的粘性分区器,与DefaultPartitioner不同的是,不管你有没有key,他都是随机选一个分区,燃弧一直发给这个分区
- 自定义分区策略
6.1 自定义分区器
public interface Partitioner extends Configurable, Closeable {
// 返回分区号
public int partition(
String topic,
Object key,
byte[] keyBytes,
Object value,
byte[] valueBytes,
Cluster cluster
);
public void close();
}
Loading...